Or wasting our time trying?
Amrit's latest post has me thinking about what's been one of our brew pub round table topics lately.
There is an old joke about the hikers who cross paths with a grizzly bear. The first hiker immediately takes off his hiking boots and puts on his running shoes.
The second hiker: “why are you doing that - you can’t out run the bear”.
First hiker: “I don’t need to out run the bear, I only need to outrun you”.
In a sense, if hacking today is focused on profit rather than challenge or ego, as perhaps it once was, then the miscreants will likely follow the least cost or least resistance path to their goal (marketable data, marketable botnets). If that is true, our goal needs to be to outrun the other hikers, not the bear.
Fortunately there appears to be a limitless supply of slow hikers (clueless developers, sysadmins, security people and their leadership, or more likely - competent developers, sysadmins and security people led astray by clueless leadership).
We need to focus on out running them, not the bear.
Presumed Hostile - Your Application is Out to Get You
OR:
Your applications are hostile, are you protecting yourself from them?
Or maybe:
The assumption that your applications are insecure and that you need to protect yourself from them should be a factor in building your security model.
The Intent:
The intent of this post is not to break new ground, but rather to describe a concept in a simple framework that can be committed to memory and become part of the 'assumed knowledge' of an organization.
The Rules:
#1 - In general, the closer a system or component is to the outside world or the more exposed the system is to the outside world (the user, the Internet or the parking lot) the less trusted it is assumed to be.
#2 - The closer a system or component is to the data (database), the higher the level of trust that must be assumed.
#3 - Any traffic or data that flows from low trust to high trust is presumed hostile. Any data flowing in that direction is assumed tainted. Any systems that are of higher trust assume that the lower trust systems are hostile. (a red arrow).
#4 - Traffic from high trust to low trust is presumed trusted. Any traffic flowing in that direction is presumed safe or trusted. (a green arrow). This one is arguable.
#5 - In between components that are of different trust levels are trust boundaries. Trust boundaries presumably are enforced by some form of access control, firewall or similar device or process. The boundaries are also assumed to be 'default deny', so that the only data or traffic that crosses the boundary is defined by and required for the application. All other data or traffic is blocked. The boundaries are also assumed to have audit logs of some kind that indicate all cases were the boundary was crossed. (a red line).
An example:
Start with a simple example. Pretend that threat is at the top of the drawing, the applications are directly exposed to the threat, and the applications are hosted on an operating system that is hosted on a platform of some kind (hardware).
 The application designer and administrators must assume that the outside world (the threat, sometimes called the customer or the Internet) is hostile and therefore they design, code, configure and monitor the application accordingly. This concept should be pretty obvious, but based on the large number of XSS and SQL injection attacks, it seems to be widely unknown or ignored.
The application designer and administrators must assume that the outside world (the threat, sometimes called the customer or the Internet) is hostile and therefore they design, code, configure and monitor the application accordingly. This concept should be pretty obvious, but based on the large number of XSS and SQL injection attacks, it seems to be widely unknown or ignored.
Applications co-located on the same operating system must implicitly distrust each other (the vertical red line). Presumably they run as different userids, they do not have write privileges in the same file space, and they assume that any data that passes between them is somehow tainted and scrub it accordingly.
The operating system administrator assumes that the applications hosted on the operating system are hostile, and designs, configures, monitors and audits the operating system according. File system and process rights are configured to least bit minimized privileges, the userids used by the application are minimally privileged, and process accounting or similar logging is used to monitor attempts to break out of the garden. The operating system also enforces application isolation in cases where the operating system hosts more than one application. Chroot jails or Solaris sparse zones are examples of application isolation.
This of course is the basic operating system hardening concept or process that has evolved over the past decade and a half.
The platform (the hardware, the keyboard, the physical ports, the Lights Out console, serial console, system controller, etc.) assumes that the operating system that booted from the platform is hostile. The operating system, when assumed to be hostile, has to be prevented from access it's own console, its own lights out interfaces, or the interface that allows firmware, BIOS or boot parameters to be modified. This presumes that access to the console automatically invalidates any security on the operating system or any layer above the OS. This also encompasses physical security.
The underlying assumption is that if the platform is compromised, everything above the platform is automatically presumed to be compromised, and if the operating system is compromised, the applications are automatically presumed to be compromised.
With Virtualization:
Adding virtualization doesn't change any of the concepts. It simply adds a layer that must be configured to protect itself against the presumed hostile virtual machines that it hosts (and of course the hostile applications on those virtual hosts).
 The most protected interface into the system, the virtual host console or management interface, must protect itself from the process that hosts the virtual machines, (the virtualization layer) and everything above it including the hosted (guest) operating system and the hosted applications on those operating systems. The operating systems hosted by the virtualization layer must protect themselves from each other (or the virtualization layer must provide that protection) and the applications hosted by the guest operating system must protect themselves from each other.
The most protected interface into the system, the virtual host console or management interface, must protect itself from the process that hosts the virtual machines, (the virtualization layer) and everything above it including the hosted (guest) operating system and the hosted applications on those operating systems. The operating systems hosted by the virtualization layer must protect themselves from each other (or the virtualization layer must provide that protection) and the applications hosted by the guest operating system must protect themselves from each other.
This has implications on how VM's get secured and managed. The operating system that is hosted by the virtualization layer should not, under any circumstances, have access to its own virtualization layer, or any management or other interface on that layer. Of course there are lots of articles, papers and blogs on how to make that happen, or on whether that can happen at all.
As in the first example, the platform must assume that the virtualization layer is hostile and must be configured to protect itself from that layer and all layers above it, and of course if the platform is compromised, everything above the platform is automatically presumed to be compromised.
For the Application Folks:
The third example conceptualizes the application layer only, specifically for those who work exclusively at the application layer. The red lines again are trust boundaries, and presumably are enforced by some form of access control, firewall or similar device or process. The concept is essentially the same as the prior examples.
 The web server administrator assumes that the Internet is hostile and designs, configures and monitors the web server according. That's pretty much a given today.
The web server administrator assumes that the Internet is hostile and designs, configures and monitors the web server according. That's pretty much a given today.
The application server administrator assumes that the web server is hostile and designs, configures and monitors the app server according. The application server administrator and the administrator of the application running on the server implicitly distrust the web server. The presumption is that any traffic from the web server has been tainted.
The DBA assumes that the application running on the app servers is hostile and designs, configures, monitors and audits the database accordingly. This means that among other things, the accounts provisioned in the database for the application are minimally privileged (least bit, not database owner or DBA) and carefully monitored by the DBA, and that 'features' like the ability to execute operating system shells and access critical database information are severely restricted. This is fundamental to deterring SQL injection and similar application layer attacks.
The database server administrator assumes that the database instance is hostile, and designs, configures and monitors the server operating system accordingly. For example the database userids do not have significant privileges on the server operating system, the file systems are configured with minimal privileges (least bit, not '777' or 'Full Control'), and the ability to shell out of the database to the operating system is restricted. The server administrator assumes that neither the application, the application servers or the database are trusted and protects the server against those assumptions. (A simple example - the database server administrator does not permit interactive logins, remote shells or RPC from the assumed hostile application or web servers.)
Conclusion:
The concept is really simple. Keep it in mind when you are at the whiteboard.
I can't be the only blogger in the universe who isn't mentioning the iPhone this weekend, so here goes. Apparently from what I read, accessing the platform (the hardware/firmware/console) pretty much invalidates all of the iPhone security at the operating system and application layer. That lines up pretty well with the concepts in this article.
Estimating the Availability of Simple Systems - Introduction
I've spent a bit of time thinking about how to estimate the expected availability of simple systems. I'm interested not in detailed calculations of complex systems, but rather in rule of thumb type of estimates for simple systems. I suspect that this problem can be as hard or as easy as one would like to make it. I'm going to try to make it easy. Wish me luck.
This post introduces the estimations. Part One covers non-redundant systems. Part Two covers simple redundant systems.
Assumptions:
I'll start out with the following assumptions:
(1) That you have a basic understanding of MTBF and MTTR.
(2) That your SLA allows for maintenance windows. Maintenance windows, if you are fortunate enough to still have them, allow 'free' outages, provided that the outage can be moved to the maintenance window.
(3) That you have the principles laid out in my availability post implemented, including:
(8) That service contracts exist, they match the SLA's, and are routinely met by the vendors. In other words if you have a two hour part replacement contract, the vendor has to have depot spares less than one hour away and deliver them in less than two hours. Not all vendors do that. And if your SLA is 24 x 7 x 365, your support and maintenance contracts are also 24 x 7 x 365.
The estimates will:
WAN links - T1's, DS3's, etc. For all non-redundant WAN links I figure an average of 4 hours per year WAN related network outage. Over hundreds of circuit-years of experience, figuring in backhoes, storms, tornadoes, circuit errors, etc, I figure that one outage every other year with an 8 hour MTTR is a reasonable estimate. Actual data from a couple hundred circuit-years of data is better that the estimate (one outage every 4 years with a 5 hour time to repair).
Routers, switches, firewalls and similar devices, booted from flash, no moving parts other than power supply fans I figure at one failure every 5 years, with the MTTR dependent on service contracts and sparing. If you have spare on hand, or you have good vendor service, your MTTR can be figured at 2 or 4 hours. If not, figure at lest 8 hours. If our network-like devices have disk drives or are based on PC components, I figure their failure rate to be the same as servers (see below).
SAN fabric, properly implemented, I figure at one failure every 5 years as with network devices, but because most SAN fabrics are built redundant, the MTTR is essentially zero, so SAN fabric errors rarely affect availability. The emphasis though, is on 'properly implemented'.
SAN LUN's, properly implemented, I figure at one failure every 10 years. But SAN LUN or controller failure, even though it is rare, likely has a very long MTTR. Recovering from failed LUN's is non-trivial, so at least 8 hours MTTR must be figured, with the potential for more, up to 24 hours.
Servers, with structured system management applied and with redundant disks, I figure at about one 8 hour outage every two years, or about 4 hours per server per year. Servers that are ad hoc managed, or servers without lights out management or redundant power supplies, I figure at about one 8 hour outage per year.
Power and cooling is highly variable. We have one data center where power/cooling issues historically have caused about 8 hours outage per year. We can't remember the last time we have a power issue in our other data center. I figure power/cooling issues on a per site basis, with estimates of 2 hours per year on the low end, and 8 hours per year on the high end.
Stacking the estimates.
Once you have a rough estimate of the availability of the various components in an application stack, you can apply them to your application.
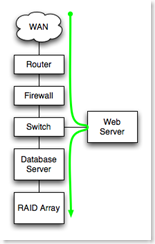 Serial Dependencies increase recovery time. In a chain of components in series, any failed component in the chain causes failure of the entire chain. In this case, the number of failures of the system is the sum of the number of failures of each series component. The recovery time for each component is also added in series.
Serial Dependencies increase recovery time. In a chain of components in series, any failed component in the chain causes failure of the entire chain. In this case, the number of failures of the system is the sum of the number of failures of each series component. The recovery time for each component is also added in series.
In the example to the right, all components from WAN at the top to RAID array at the bottom are serially dependent. Each must function for the application to function, and failure of a component is a failure of the application.
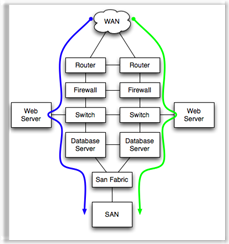 Parallel Dependencies improve recovery time. Components in parallel, properly configured for some form of automatic load balancing or failover, have an MTTR equal to the failover time for the pair of parallel components. Examples would be Microsoft Clustering Services, high availability firewall pairs, load balanced application servers, etc. In each of those cases, the high availability technology has a certain time window for detecting and disabling the failed component and starting the service on the non-failed parallel component. Parallel component failover and recovery times typically range from a few seconds to a few minutes.
Parallel Dependencies improve recovery time. Components in parallel, properly configured for some form of automatic load balancing or failover, have an MTTR equal to the failover time for the pair of parallel components. Examples would be Microsoft Clustering Services, high availability firewall pairs, load balanced application servers, etc. In each of those cases, the high availability technology has a certain time window for detecting and disabling the failed component and starting the service on the non-failed parallel component. Parallel component failover and recovery times typically range from a few seconds to a few minutes.
In the example to the left, if either the green or the blue path is available, the application will function.
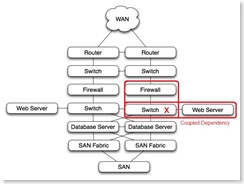 Coupled dependencies, as in the firewall-> switch -> web server stack shown, force the failure of dependent components when a single component fails. In this case, if the switch were to fail, the web sever would also fail, and the firewall, if active, would also see a failed interface and force a failover to the other firewall.
Coupled dependencies, as in the firewall-> switch -> web server stack shown, force the failure of dependent components when a single component fails. In this case, if the switch were to fail, the web sever would also fail, and the firewall, if active, would also see a failed interface and force a failover to the other firewall.
Coupled dependencies tend to be complex. Identification and testing of coupled dependencies ensures that the various failure modes of coupled components are well understood and predictable. Technologies like teamed nic's and etherchannel can be used to de-couple dependencies.
On to Part One - Non Redundant Systems
This post introduces the estimations. Part One covers non-redundant systems. Part Two covers simple redundant systems.
Assumptions:
I'll start out with the following assumptions:
(1) That you have a basic understanding of MTBF and MTTR.
(2) That your SLA allows for maintenance windows. Maintenance windows, if you are fortunate enough to still have them, allow 'free' outages, provided that the outage can be moved to the maintenance window.
(3) That you have the principles laid out in my availability post implemented, including:
- Tier 1 hardware with platform management software installed, configured and tested. (Increases MTBF, Decreases MTTR)
- Stable power, UPS and generator. (Increases MTBF)
- Staff are available during SLA hours, either officially working or available via some form of on-call. (Decreases MTTR)
- Structured System Management implemented. (Increases MTBF, Decreases MTTR)
- Service contracts that match application SLA's. (Decreases MTTR)
- You have well designed, reliable power and cooling. (Increases MTBF)
- You have remote management, lights out boards and remote consoles on all devices.
(5) That you understand where you have coupled dependencies. Examples:
- In a typical redundant router -> switch -> firewall stack, a failure of the switch will cause interfaces on the router and firewall to fail. Those interface failures will trigger an HA failover on both the HA router pair and the HA firewall pair.
- In a typical dual powered rack, devices with single power supplies configured in HA pairs and are connected such that power failure of one side of the racks leaves the correct half of the HA pair still running.
(6) That you have Tier 1 hardware from a major manufacturer with platform management software installed, configured and tested. You need the predictive failure messages that modern servers are capable of generating showing up on your SMS device. Predictive failure doesn't change the rate at which components fail, but it allows you you proactively schedule replacement of failed components during maintenance windows. This gives you 'freebie' failed component replacement. If you do not have Tier 1 hardware and do not have platform management software configured, your failure rate and your recovery time will will both increase.
(7) That staff are available during SLA hours, either officially working or available via some kind of on-call.
The estimates will:
- Be conservative estimates, with plenty of room for error.
- Include operating system issues.
Include hardware issues
The major components I'll cover are:
- Wan Links
- Routers, switches, firewalls and similar devices
- SAN fabrics
- SAN LUNs
- Servers
- Power and Cooling
Excluded from the estimates are:
- Databases, database issues, database performance problems.
- Web Applications, including performance problems, configuration problems.
Once-in-a lifetime events (like an Interstate bridge falling down 100 meters from your data center). - The human factor.
A handy chart
A chart of failure and MTTR assumptions might be handy. I'll express failure and recovery in hours per year. The math is pretty simple. Number of failure per year * hours to recover = hours failed per year. It can be converted to 'nines' later.
| Component | Failures per Year | Hours to Recover | Hours Failed per year |
| WAN Link | .5 | 8 | 4 |
| Routers, Devices | .2 | 4 | .8 |
| SAN Fabric | .2 | 4 | .8 |
| SAN LUN | .1 | 12 | .12 |
| Server | .5 | 8 | 4 |
| Power/Cooling | 1 | 2 | 2 |
WAN links - T1's, DS3's, etc. For all non-redundant WAN links I figure an average of 4 hours per year WAN related network outage. Over hundreds of circuit-years of experience, figuring in backhoes, storms, tornadoes, circuit errors, etc, I figure that one outage every other year with an 8 hour MTTR is a reasonable estimate. Actual data from a couple hundred circuit-years of data is better that the estimate (one outage every 4 years with a 5 hour time to repair).
Routers, switches, firewalls and similar devices, booted from flash, no moving parts other than power supply fans I figure at one failure every 5 years, with the MTTR dependent on service contracts and sparing. If you have spare on hand, or you have good vendor service, your MTTR can be figured at 2 or 4 hours. If not, figure at lest 8 hours. If our network-like devices have disk drives or are based on PC components, I figure their failure rate to be the same as servers (see below).
SAN fabric, properly implemented, I figure at one failure every 5 years as with network devices, but because most SAN fabrics are built redundant, the MTTR is essentially zero, so SAN fabric errors rarely affect availability. The emphasis though, is on 'properly implemented'.
SAN LUN's, properly implemented, I figure at one failure every 10 years. But SAN LUN or controller failure, even though it is rare, likely has a very long MTTR. Recovering from failed LUN's is non-trivial, so at least 8 hours MTTR must be figured, with the potential for more, up to 24 hours.
Servers, with structured system management applied and with redundant disks, I figure at about one 8 hour outage every two years, or about 4 hours per server per year. Servers that are ad hoc managed, or servers without lights out management or redundant power supplies, I figure at about one 8 hour outage per year.
Power and cooling is highly variable. We have one data center where power/cooling issues historically have caused about 8 hours outage per year. We can't remember the last time we have a power issue in our other data center. I figure power/cooling issues on a per site basis, with estimates of 2 hours per year on the low end, and 8 hours per year on the high end.
Your assumptions for failure frequency and recovery time might be different than mine.
Once you have a rough estimate of the availability of the various components in an application stack, you can apply them to your application.
First steps:
- Sketch out your application stack
- Identify each component
- Identify parallel verses serial dependencies
- Identify coupled dependencies
 Serial Dependencies increase recovery time. In a chain of components in series, any failed component in the chain causes failure of the entire chain. In this case, the number of failures of the system is the sum of the number of failures of each series component. The recovery time for each component is also added in series.
Serial Dependencies increase recovery time. In a chain of components in series, any failed component in the chain causes failure of the entire chain. In this case, the number of failures of the system is the sum of the number of failures of each series component. The recovery time for each component is also added in series.In the example to the right, all components from WAN at the top to RAID array at the bottom are serially dependent. Each must function for the application to function, and failure of a component is a failure of the application.
 Parallel Dependencies improve recovery time. Components in parallel, properly configured for some form of automatic load balancing or failover, have an MTTR equal to the failover time for the pair of parallel components. Examples would be Microsoft Clustering Services, high availability firewall pairs, load balanced application servers, etc. In each of those cases, the high availability technology has a certain time window for detecting and disabling the failed component and starting the service on the non-failed parallel component. Parallel component failover and recovery times typically range from a few seconds to a few minutes.
Parallel Dependencies improve recovery time. Components in parallel, properly configured for some form of automatic load balancing or failover, have an MTTR equal to the failover time for the pair of parallel components. Examples would be Microsoft Clustering Services, high availability firewall pairs, load balanced application servers, etc. In each of those cases, the high availability technology has a certain time window for detecting and disabling the failed component and starting the service on the non-failed parallel component. Parallel component failover and recovery times typically range from a few seconds to a few minutes.In the example to the left, if either the green or the blue path is available, the application will function.
 Coupled dependencies, as in the firewall-> switch -> web server stack shown, force the failure of dependent components when a single component fails. In this case, if the switch were to fail, the web sever would also fail, and the firewall, if active, would also see a failed interface and force a failover to the other firewall.
Coupled dependencies, as in the firewall-> switch -> web server stack shown, force the failure of dependent components when a single component fails. In this case, if the switch were to fail, the web sever would also fail, and the firewall, if active, would also see a failed interface and force a failover to the other firewall.Coupled dependencies tend to be complex. Identification and testing of coupled dependencies ensures that the various failure modes of coupled components are well understood and predictable. Technologies like teamed nic's and etherchannel can be used to de-couple dependencies.
On to Part One - Non Redundant Systems
Estimating the Availability of Simple Systems - Non-redundant
In the Introductory post to this series, I outlined the basics for estimating the availability of simple systems. This post picks up where the first post left off and attempts to look at availability estimates for non-redundant systems.
Let's go back to the failure estimate chart from the introductory post
| Component | Failures per Year | Hours to Recover | Hours Failed per year |
| WAN Link | .5 | 8 | 4 |
| Routers, Devices | .2 | 4 | .8 |
| SAN Fabric | .2 | 4 | .8 |
| SAN LUN | .1 | 12 | .12 |
| Server | .5 | 8 | 4 |
| Power/Cooling | 1 | 2 | 2 |
And apply it to a simple stack of three non-redundant devices in series.  Assuming that the devices are all 'boot from flash and no hard drive' we would apply the estimated failures per year and hours to recover in series for each device from the Routers/Devices row of the table. For series dependencies, where the availability of the stack depends on each of the devices in the stack, simply adding the estimated failures and recovery times together gives us an estimate for the entire stack.
Assuming that the devices are all 'boot from flash and no hard drive' we would apply the estimated failures per year and hours to recover in series for each device from the Routers/Devices row of the table. For series dependencies, where the availability of the stack depends on each of the devices in the stack, simply adding the estimated failures and recovery times together gives us an estimate for the entire stack.
For each device:
.2 failures/year * 4 hours to recover = .8 hours/year unavailability.
For three devices in series, each with approximately the same failure rate and recovery time, the unavailability estimate would be the sum of the unavailability of each component, or .8 + .8 + .8 = 2.4 hours/year.
Notice a critical consideration. The more non-redundant devices you stack up in series, the lower your availability. (Notice I made that sentence in bold and italics. I did that 'cause it's a really important concept.)
The non-redundant series dependencies also apply to other interesting places in a technology stack. For example, if I want my really big server to go faster, I add more memory modules so that the memory bus can stripe the memory access across more modules and spend less time waiting for memory access. Those memory modules are effectively serial, non-redundant. So for a fast server, we'd rather have 16 x 1GB DIMMs than 8 x 2GB DIMMs or 4 x 4GB DIMMs. The server with 16 x 1GB DIMMs will likely go faster than the server with 4 x 4DB DIMMs, but it will be 4 times as likely to have memory failure.
Let's look at a more interesting application stack, again a series of non-redundant components.
We'll assume that this is a T1 from a provider, a router, firewall, switch, application/web server, a database server and attached RAID array. The green path shows the dependencies for a successful user experience. The availability calculation is a simple sum of the product of failure frequency and recovery time of each component.

| Component | Failures per Year | Hours to Recover | Hours Failed per year |
| WAN Link | 0.5 | 8 | 4.0 |
| Router | 0.2 | 4 | 0.8 |
| Firewall | 0.2 | 4 | 0.8 |
| Switch | 0.1 | 12 | .12 |
| Web Server | 0.5 | 8 | 4.0 |
| Database Server | 0.5 | 8 | 4.0 |
| RAID Array | 0.1 | 12 | .12 |
| Power/Cooling | 1.0 | 2 | 2.0 |
| Total | 15.8 hours |
The estimate for this simple example works out to be about 16 hours of down time per year, not including any application issues, like performance problems, scalability issues.
- The estimate also doesn't consider the human factor.
- Because numbers we input into the chart are really rough, with plenty of room for error, the final estimate is also just a guesstimate.
- The estimate is the average hours of outage over a number of years, not the number of hours of outage for each year. You could have considerable variation from year to year.
Applying the Estimate to the Real World
To apply this to the real world and estimate an availability number for the entire application, you'd have to know more about the application, the organization, and the persons managing the systems.
For example - assume that the application is secure and well written, and that there are no scalability issues, and assume that the application has version control, test, dev and QA implementations and a rigorous change management process. That application might suffer few if any application related outages in a typical year. Figure one bad deployment per year that causes 2 hours of down time. On the other hand, assume that it is poorly designed, that there is no source code control or structured deployment methodology, no test/QA/dev environments, and no change control. I've seen applications like that have a couple hours a week of down time.
And - if you consider the human factor, that the humans in the loop (the keyboard-chair interface) will eventually mis-configure a device, reboot the wrong server, fail to complete a change within the change window, etc., then you need to pad this number to take the humans into consideration.
On to Part Two (or back to the Introduction?)
Estimating the Availability of Simple Systems - Redundant
This is a continuation of a series of posts that attempt to provide the basics of estimating the availability of various simple systems. The Introduction covered the fundamentals, Part One covered estimating the availability of non-redundant systems. This post will attempt to cover simple redundant systems.
Let's go back to the failure estimate chart from the introductory post, but this time modify it for redundant (active/passive) redundancy. Remember that for redundant components, the number of failures is the same (the MTBF doesn't change), but the time to recover (MTTR) is shortened dramatically. The MTTR is no longer the time it takes to determine the cause of the failure and replace the failed part, but rather the MTTR is the time that it takes to fail over to the redundant component.
| Component | Failures per Year | Hours to Recover (component) | Hours to failover (redundant) | Hours Failed per year |
| WAN Link | .5 | 8 | .05 | .025 |
| Routers, Devices | .2 | 4 | .05 | .01 |
| SAN Fabric | .2 | 4 | .01 | .002 |
| SAN LUN | .1 | 12 | .12 | .12 |
| Server | .5 | 8 | .05 | .025 |
| Power/Cooling | .2 | 2 | 0 | 0 |
Notice nice small numbers in the far right column. Redundant systems tend to do a nice job of reducing MTTR.
Note that if you believe in complexity and the human factor, you might argue that because they are more complex, redundant systems have more failures. I'm sure this is true, but I haven't considered that for this post (yet). Note also that I consider SAN LUN failure to be the same as for the non-redundant case. I've considered that LUN's are always configured with some for on redundancy, even in the non-redundant scenario.
 Now apply it to a typical redundant application stack. The stack mixed active/active, active passive. There are differences in failure rates of active/active and active/passive HA pairs, but for this post, the difference is minor enough to ignore. (Half the time, when a active/passive pair has a failure, the passive device is the one that failed, so service is unaffected. Active/active pairs therefor have a service affecting failure twice as often.)
Now apply it to a typical redundant application stack. The stack mixed active/active, active passive. There are differences in failure rates of active/active and active/passive HA pairs, but for this post, the difference is minor enough to ignore. (Half the time, when a active/passive pair has a failure, the passive device is the one that failed, so service is unaffected. Active/active pairs therefor have a service affecting failure twice as often.)
Under normal operation, the green devices are active, and failure of any active device causes an application outage equal to the failover time of the high availability device pair.
The estimates for failure frequency and recovery time are:
| Component | Failures per Year | Hours to failover (MTTR) | Hours Failed per year |
| WAN Link | .5 | .05 | .025 |
| Router | .2 | .05 | .01 |
| Firewall | .2 | .05 | .01 |
| Load Balancers | .2 | .05 | .01 |
| Switch | .2 | .05 | .01 |
| Web Server | .5 | .05 | .025 |
| Switch | .2 | .05 | .01 |
| Database Server | .5 | .05 | .025 |
| SAN Fabric | .2 | .01 | .002 |
| SAN LUN | .1 | .12 | .12 |
| Power/Cooling | 1 | 0 | 0 |
| Total | .25 = 15 min |
These numbers imply some assumptions about some of the components. For example, in this trivial case, I'm assuming that :
- The WAN links must not be in the same conduit, or terminate on the same device at the upstream ISP. Otherwise they would not be considered redundant. Also, the WAN links likely will be active/active, so the probability of failure will double.
- Networks, Layer 3 verses Layer 2. I'll go out on a limb here. In spite of what vendors promise, under most conditions, layer 2 redundancy (i.e. spanning tree managed link redundancy) does not have higher availability than a similarly designed network with layer 3 redundancy (routing protocols). My experience is that the phrase 'friends don't let friends run spanning tree' is true, and that the advantages gained by the link redundancy provided by layer 2 designs are outweighed by the increased probability of spanning tree loop related network failure.
- Power failures are assumed to be covered by battery/generator. But many hosting facilities still have service affecting power/cooling failures. If I were presenting theses numbers to a client, I'd factor in power and cooling somehow, perhaps by guesstimating a hour or so per year, depending on the facility
These numbers look pretty good, but don't start jumping up and down yet.
Humans are in the loop, but not accounted for in this calculation. As I indicated in the human factor, the human can, in the case where redundant systems are properly designed and deployed, be the largest cause of down time (the keyboard-chair interface is non-redundant). Also, there is no consideration for the application itself (bugs, bad failed deployments) or consideration for the database (performance problems, bugs). As indicated in previous post, a poorly designed application that is down every week because of performance issues or bugs isn't going to magically have fewer failures because it is moved to redundant systems. It will just be a poorly designed, redundant application.
Coupled Dependencies
 A quick note on coupled dependencies. In the example above, the design is such that the load balancer, firewall and router are coupled. (In this design they are, in other designs they are not). A hypothetical failure of the active firewall would result in a firewall failover, a load balancer failover, and perhaps a router HSRP failover. The MTTR would be the time it takes for all three devices to figure out who is active.
A quick note on coupled dependencies. In the example above, the design is such that the load balancer, firewall and router are coupled. (In this design they are, in other designs they are not). A hypothetical failure of the active firewall would result in a firewall failover, a load balancer failover, and perhaps a router HSRP failover. The MTTR would be the time it takes for all three devices to figure out who is active. Coupled dependencies tend to cause unexpected outages themselves. Typically, when designing systems with coupled dependencies, thorough testing is needed to uncover unexpected interactions between the coupled devices. (In the case shown here interaction between HRSP, the routing protocol, the active/passive firewall, and layer 2 redundancy at the switch layer is complex enough to be worth a day in the lab.)
Conclusions
- Structured System Management has the greatest influence on availability.
- With non-redundant but well managed systems, the human factor will be significant, but should not be the major cause of outages.
- With redundant, well managed systems, the human factor may be the largest cause of outages.
- A poorly designed or written application will not be improved by redundancy.
Keep in mind that the combination of application, human and database outages, not considered in the calculation, will far outweigh simple hardware and operating system failures. For your estimations, you will have to add failures and recovery time for human failure, application failure and database failure. (Hint - figure a couple hours each per year.)
As indicated in the introductory post, I tried.
Back to the Introduction (or the previous post).
Estimating the Availability of Simple Systems
As system managers, we are tasked with building and maintaining systems that are expected to be ‘always on’. Our objective of course, is to bridge the gap between our users definition of ‘always on’ and our accountants definition of ‘under budget’. In my experience, the gap tends to be large.
With that goal in mind, I’ve outlined a method for quickly estimating expected availability for simple systems, or ‘application stacks’. For purposes of these posts, a system includes power, cooling, WAN, network, servers and storage.
The introductory post outlines the basics for estimating the availability of simple systems, the assumptions used when estimating availability, and the basics of serial, parallel and coupled dependencies.
Part one covers estimating the availability of simple non-redundant systems.
Part two covers estimating the availability of systems with simple active/passive redundancy.
My hope is that there prove useful as rules of thumb for bridging the gap between user expectations and the realities of the systems on which they depend.
With that goal in mind, I’ve outlined a method for quickly estimating expected availability for simple systems, or ‘application stacks’. For purposes of these posts, a system includes power, cooling, WAN, network, servers and storage.
The introductory post outlines the basics for estimating the availability of simple systems, the assumptions used when estimating availability, and the basics of serial, parallel and coupled dependencies.
Part one covers estimating the availability of simple non-redundant systems.
Part two covers estimating the availability of systems with simple active/passive redundancy.
My hope is that there prove useful as rules of thumb for bridging the gap between user expectations and the realities of the systems on which they depend.
The Pew Broadband Report and the Digital Divide
The digital divide appears to be more complicated than we thought. From the 2008 Pew Home Broadband Report it looks like only a fraction of non-Internet users are actually held back by the availability of broadband. A whole bunch of non-users are simply not interested, and another large group doesn't have the money. The plethora of task forces that meet to talk endlessly about the digital divide need to think about cost and interest, not just availability.
Among people who do not use the Internet (27% of adult Americans)
In any case, a number of potential Internet users are still using dial-up, not broadband. If you take dial up users and lump them in with mobile and PDA users, you have a class of people that have Internet access, but the access is restricted in some way, either by bandwidth or device capability. Call them 'low capability users'. Low bandwidth dial up users are shrinking, but low capability device users are growing (mobile phone, PDA, and iPhone users). If you develop applications, you need to keep the low capability users on the radar. They are not going to go away.
The BBC figured this out. I can access the majority of their content with low bandwidth, low capability GPRS or EDGE devices, with high bandwidth devices, and with everything in between. They get it.
The bottom line is that a segment of your users are, and for the foreseeable future will be using low capability devices, either dial-up, mobile, PDA or iPhones. If those users are not able to use an application, they are excluded not by the device or Internet access technology that they choose to use, but rather by the application or site design that excludes those users.
Among people who do not use the Internet (27% of adult Americans)
When asked why they don’t use the internet:
- 43% of non-internet users are over the age of 65 or, put differently, 65% of senior citizens do not use the internet.
- 43% of non-internet users have household incomes under $30,000 per year.
So we have an age problem, which will eventually will resolve itself (Old people tend to go away eventually), an income problem, and a simple lack of interest. A large number of people, 33% + 7% of those who are not connected simply don't want to be connected. Apparently we have not created a compelling reason to convince the un-interested people that the Internet has value. A small number of Internet users are still using dial up. And among dial-up users:
- 33% of non-users say they are not interested.
- 12% say they don’t have access.
- 9% say it is too difficult or frustrating.
- 7% say it is too expensive.
- 7% say it is a waste of time.
Among the 10% of Americans (or 15% of home internet users) with dial-up at home:So the issue of converting dial up users to broadband is not simply that broadband isn't available (10%). The largest segment of the dial up population is waiting for the price to drop. The second largest segment isn't going to get broadband no matter what. This is not an availability issue, it is a cost issue and an I don't care issue.
- 35% of dial-up users say that the price of broadband service would have to fall.
- 19% of dial-up users said nothing would convince them to get broadband.
- 10% of dial-up users – and 15% of dial-up users in rural America – say that broadband service would have to become available where they.
In any case, a number of potential Internet users are still using dial-up, not broadband. If you take dial up users and lump them in with mobile and PDA users, you have a class of people that have Internet access, but the access is restricted in some way, either by bandwidth or device capability. Call them 'low capability users'. Low bandwidth dial up users are shrinking, but low capability device users are growing (mobile phone, PDA, and iPhone users). If you develop applications, you need to keep the low capability users on the radar. They are not going to go away.
The BBC figured this out. I can access the majority of their content with low bandwidth, low capability GPRS or EDGE devices, with high bandwidth devices, and with everything in between. They get it.
The bottom line is that a segment of your users are, and for the foreseeable future will be using low capability devices, either dial-up, mobile, PDA or iPhones. If those users are not able to use an application, they are excluded not by the device or Internet access technology that they choose to use, but rather by the application or site design that excludes those users.
Accident
It's the end of a long day, I'm a thousand miles from home, on a rural Montana road driving not too far over the speed limit. There is nothing around - except - what's that?
The neural net kicks in. Somewhere in the vast emptiness between my ears, the pattern matching algorithm registers a hit, the bell dings, the right leg stomps the middle pedal, the left leg stomps the left pedal, the ABS brakes kick in, the flashers go on and the Subaru stops. In the ditch is a person kneeling, a lump of something potentially sentient, and a badly bent motorcycle, wheels up.
Yep - I'm first on the scene of a motorcycle accident. They aren't hard to recognize, especially if you've seen a whole bunch of them during your motorcycle road racing phase.
Now what the heck do I do? I'm not trained in anything like first aid. The only rule I could remember from high school first aid is 'Remain Calm'. Ok - I'm calm, now what? What's rule number two? Damn - can't remember.
A quick survey - the victim is breathing, conscious, alert, but with various limbs pointing in non-standard directions. There are no fluid leaks. Presumably she is going to be OK, but she certainly isn't going to move until someone with proper equipment gets on the scene. The victims husband is already calling 911, so that is covered. Just about the time that I'm figuring I'm going to have to actually do something, help arrives. Not the official help from 911, but rather a Pennsylvania tourist-lady, who just happens to be an EMT, a paramedic, an emergency room nurse. Whew.......
The paramedic/tourist (name forgotten) took charge, did basic analysis, and gave me something useful to do (keep the victim from hurting herself any worse, hold her head and keep her from moving....). The first pass at a diagnosis - one busted arm, one dislocated hip, and no other serious injuries.
Now the motorcycle road racing experience gets relevant. I remember that post-crash, one doesn't feel pain. They tell me that adrenalin from the crash masks the pain - for a while. (In one of my own crashes, I remember arguing with the paramedic about the extent of my injury. He insisted my shoulder was dislocated, I insisted it wasn't. He was right. I couldn't feel it - the adrenalin numbed me.)
Unfortunately for the crash victim, the adrenalin pain mask didn't last long enough. A few minutes later, the pain kicked in. And the victim, in obvious severe pain, did what bikers do - she gritted her teeth and took the pain as it came. She's tough, real tough.
I'm pretty sure that in rural Montana, most or all of the emergency workers are volunteers. The volunteers arrived, some directly from home in their personal vehicles, others with the official ambulance. The first thing they did was a neck brace. Preventing neck/back damage seems to be priority - at least it is if the person is breathing, beating and not leaking too badly. I got the privilege of assisting on the neck brace. Then - with the ditch full of people who know what to do, and the road full of shiny, expensive vehicles with flashing lights, I bailed.
The Pennsylvania tourist-lady? She was cool - on the way back to the cars, she admitted that she did emergency work for the thrill. She lived to help people, and to get a rush doing it.
I wonder if the victim had insurance?
Subscribe to:
Posts (Atom)
-
Cargo Cult: …imitate the superficial exterior of a process or system without having any understanding of the underlying substance --Wikipe...
-
Structured system management is a concept that covers the fundamentals of building, securing, deploying, monitoring, logging, alerting, and...
-
In The Cloud - Outsourcing Moved up the Stack [1] I compared the outsourcing that we do routinely (wide area networks) with the outsourcing ...
