When person-resources are constrained, highest availability is achieved when the system is designed with the minimum complexity necessary to meet availability requirements.My hypothesis, that minimizing complexity maximizes availability, assumes that in an environment where the number of persons is constrained or fixed, as systems become more complex the human factors in system failure and resolution become more important than technology factors.
This hypothesis also assumes that increased system availability generally presumes an increase in complexity. I am basing this on a combination of a simple analysis of availability combined with extensive experience managing technology.
Person Resources vs Complexity
- As availability requirements are increased, the technology required becomes more complex.
- As the technology gets more complex, the person-resources to manage the technology increases.
- Resources are generally constrained, so the ideal resource allocation is unlikely to occur in the real world.
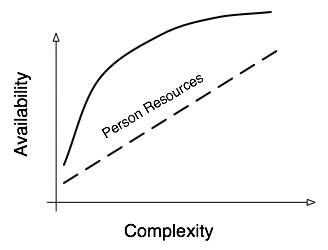 In an ideal organization, as system availability requirements go up, both person-resources and technology resources would increase as necessary to support the increased availability requirement. The relationship between availability and person resources should look something like the first chart. In theory the initial investment in structured system management and simple redundancy will result in a large improvement in availability relative to the resources spent. Moving from ad-hoc system management toward structured system management will result in fewer unplanned downtimes and less time spent troubleshooting problems, so both MTBF and MTTR should improve. Moving from non-redundant systems to simple redundancy (load balanced app servers, active/passive firewall and network failover, active/passive clustering, etc) will result in faster recovery time on failures, so even though the MTBF will not improve, MTTR will improve, therefore availability will improve.
In an ideal organization, as system availability requirements go up, both person-resources and technology resources would increase as necessary to support the increased availability requirement. The relationship between availability and person resources should look something like the first chart. In theory the initial investment in structured system management and simple redundancy will result in a large improvement in availability relative to the resources spent. Moving from ad-hoc system management toward structured system management will result in fewer unplanned downtimes and less time spent troubleshooting problems, so both MTBF and MTTR should improve. Moving from non-redundant systems to simple redundancy (load balanced app servers, active/passive firewall and network failover, active/passive clustering, etc) will result in faster recovery time on failures, so even though the MTBF will not improve, MTTR will improve, therefore availability will improve.
When simple active/passive redundancy is no longer adequate to achieve required availability, system complexity is greatly increased. Availability targets that require active/active clustering, multi-homed servers, redundant data centers, layer-2 network redundancy with sub-minute recovery times require more person-resource  relative to the resulting increase in availability. If person-resources are added along with the necessary technology resources, the availability will continue to increase.
relative to the resulting increase in availability. If person-resources are added along with the necessary technology resources, the availability will continue to increase.
If however, person-resources are not available to support the increase complexity brought on by the increased availability requirements, the availability curve will look something like the second chart. The systems will be complex to manage, but the existing person-resources, if not supplemented, will be unable to adequately design, test, deploy the more complex environment. Most importantly though, in the event of a failure of the more complex environment, more time will be spent troubleshooting and resolving problems, potentially increasing MTTR and decreasing availability.
This may be nothing more that a restatement of the K.I.S.S principle.
Related Posts:
Estimating Availability of Simple Systems – Introduction
Estimating Availability of Simple Systems - Non-redundant
Estimating Availability of Simple Systems – Redundant
Availability, Longer MTBF and shorter MTTR
Availability - MTBF, MTTR and the Human Factor
(2008-07-19 -Updated links, minor edits)

No comments:
Post a Comment